
The Semantic Layer: Why now ?
Three forces making the semantic layer unavoidable in 2026


The semantic layer is not a new idea. Data architects have debated abstraction layers, metric stores, and headless BI for the better part of a decade. So why is it suddenly everywhere - in every conference keynote, every CDO agenda, every vendor pitch deck of 2026?
Three forces have converged at the same moment. Each makes the semantic layer not just useful, but structurally necessary. Miss any one of them and you’re making architectural decisions based on last decade’s requirements.

Force 01 : The AI analytics reckoning
LLMs can query your data - but they can’t trust it without you
In 2025, nearly every analytics vendor shipped some version of natural language querying. Ask a question in plain English, get a chart. The demos were impressive. The production reality was sobering.
A survey of over 330 data teams found average confidence in AI query results at just 5.5 out of 10. People with deeper technical knowledge trusted the outputs even less - because they understood what was happening under the hood.
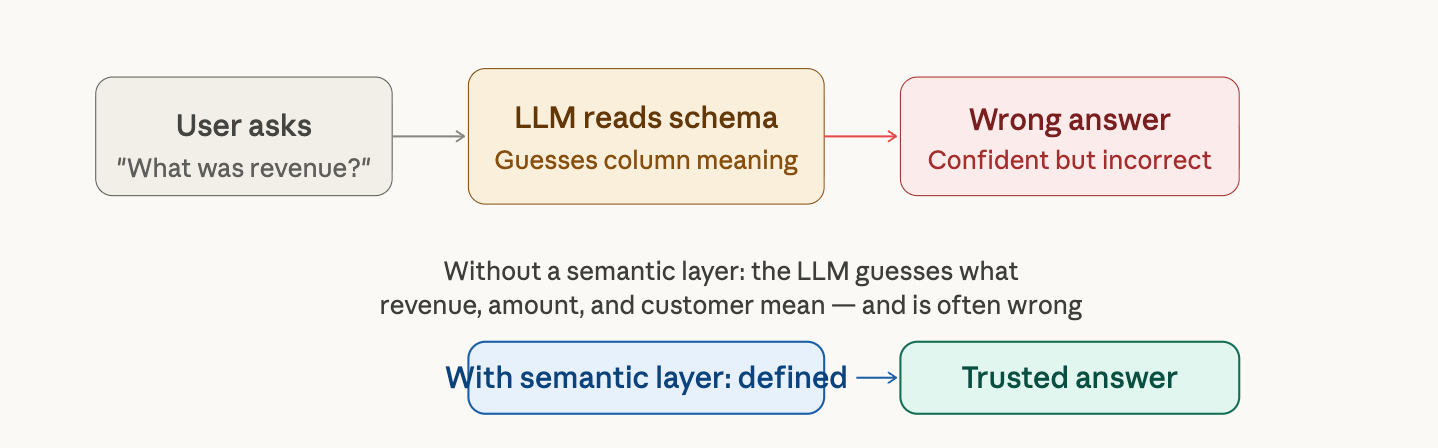
The problem is not the AI. The problem is what the AI is pointing at. When a model queries a database, it sees column names like amount, rev_adj, or cust_id and has to guess what they mean. The model picks something plausible and generates SQL that looks correct - but produces the wrong number.
“2025 was about building agents. 2026 is about trusting them.” — Michael Ni, Constellation Research
The semantic layer solves this by giving AI something concrete to reason over. Metrics have names. Business logic is baked in. Revenue means exactly one thing - defined once, inherited everywhere. When an AI assistant queries through a governed semantic layer, it is not guessing. It is working from a blueprint.
Gartner projects that by 2026, 40% of analytics queries will be generated using natural language. The semantic layer is what makes those queries trustworthy.
Force 02 : The data product reckoning
Decentralized ownership needs a centralized contract layer
Across the data industry, a fundamental shift is underway: teams are moving from treating data as a by-product of their systems to treating it as a product in its own right - something with an owner, a contract, a quality standard, and a defined audience.
You don’t need to have heard of data mesh to be living this shift. Finance has a “revenue data product.” Marketing has a “customer data product.” The platform team has published a “transactions data product.” Each is owned, versioned, and maintained by a domain team.
And here is the problem that nobody saw coming: when multiple teams independently define the same concepts, you don’t get consistency - you get fragmentation at scale.
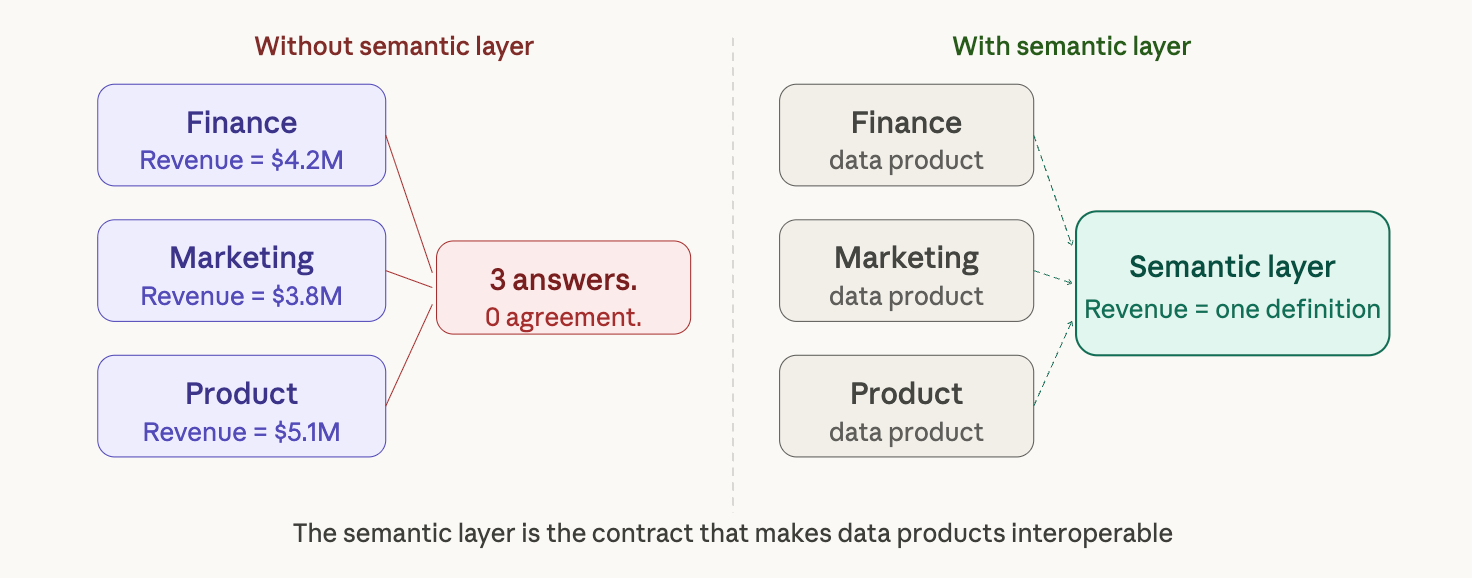
This is where the semantic layer becomes the contract layer - not a centralization mechanism, but a shared agreement about what things mean. Finance’s revenue data product and Marketing’s revenue data product should resolve to the same number when they are both querying through a governed semantic model. Without it, every new data product published adds another definition of every shared metric.
Organizations adopting data products report faster analytics delivery and domain teams that focus on outcomes rather than waiting for central IT. The catch: that speed advantage evaporates the moment two products define the same metric differently. The semantic layer is what preserves the speed while enforcing the consistency.
There is a sharper version of this problem emerging. As AI agents begin consuming data products directly - not humans, but autonomous systems making operational decisions - the cost of a mismatched definition moves from “confusing dashboard meeting” to “wrong automated action at scale.” Data contracts are already becoming a 2026 trend for exactly this reason. The semantic layer is what makes those contracts enforceable.
Force 03 : Self-service pressure has hit its limit
Business users won’t wait - and the data team can’t scale to meet them
Every CDO has heard some version of this: the business wants self-service. They want to ask questions without filing a ticket. They want answers this week, not next sprint. The usual response has been to deploy more BI tools. And three years later, the data team is maintaining six tools, fielding questions about why numbers don’t match, and still drowning in requests.
The tools were never the bottleneck. The semantics were.
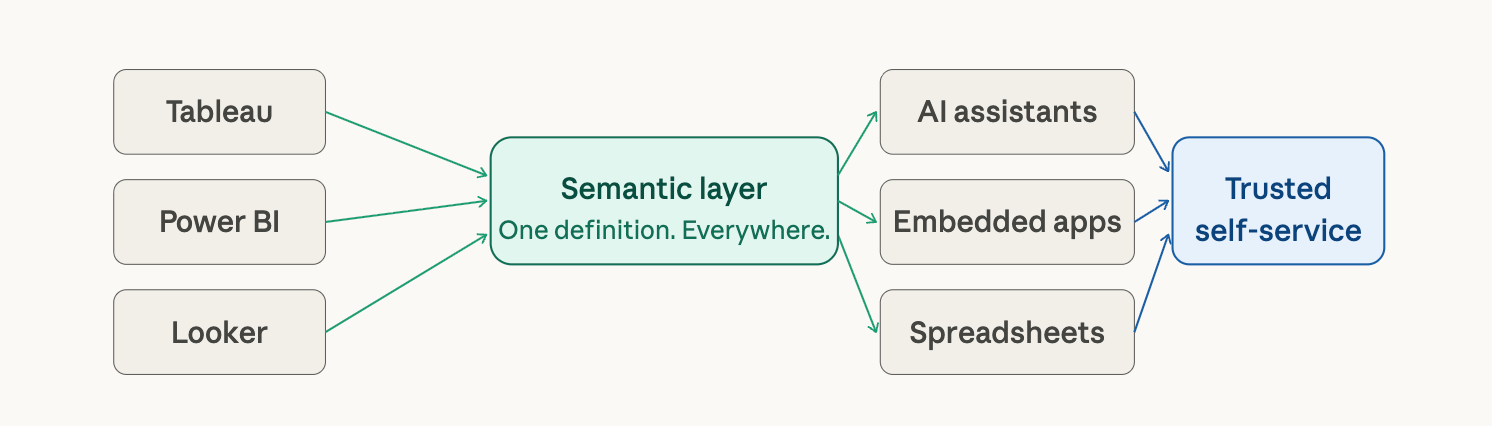
Self-service only works when every tool draws from the same governed definitions. When revenue is defined once and inherited by every BI tool, AI assistant, and embedded application, self-service actually delivers on its promise. Without it, each new tool creates a new definition of each metric - and the data team becomes the forensic accountant.
A 2026 study found that 80% of employees will consume insights directly within the business apps they use every day - CRM, ERP, collaboration tools. That level of embedded analytics is only sustainable with a semantic layer underneath it.
Three forces. One decision. The cost of not acting is now visible: AI you can’t trust, a data mesh that produces drift, and self-service that creates more questions than it answers. The tooling has matured - dbt, Cube, AtScale, and platform-native options in Snowflake and Databrics have all lowered the barrier. What remains hard is the organizational work: getting stakeholders to agree on definitions, and getting leadership to treat the semantic layer as infrastructure rather than overhead. That is what the next issues of this series will tackle.
#DataStrategy #SemanticLayer #DataLeadership #DataMesh #AIAnalytics #TheDataBrief